
名前だけ聞いたことがあるローカルLLMとは
最近、XなどでローカルLLMという言葉を見かける機会が増えてきました。AIについて興味を持って積極的に調べている人はそれなりに知っているかもしれませんが、それ以外の人にとっては少し難しそうに感じますよね。
ChatGPTみたいなもの?
自分のパソコンでAIを動かせるってこと?
普通のパソコンでも使えるの?
このあたりが気になる人も多いと思います。ローカルLLMを簡単に言うと、ChatGPTのようなAIを、自分のパソコンの中で動かす仕組み のことです。
普段使っているChatGPTやClaude、Geminiなどは、インターネットを通じて外部のサーバーにアクセスして使います。一方でローカルLLMは、自分のパソコンにAIモデルをダウンロードして、そのパソコン上で文章の生成や質問への回答を行います。
まずは、ローカルLLMを理解するために、そもそもLLMとは何かから見ていきます。
そもそもLLMとは
LLMとは、Large Language Model の略です。日本語では大規模言語モデルと呼ばれます。
少し難しく聞こえますが、ざっくり言うと、大量の文章を学習して、人間のように文章を理解したり作ったりできるAI のことです。たとえば、LLMは以下のようなことができます。
- 質問に答える
- 文章を要約する
- メール文を作る
- 翻訳する
- プログラムのコードを書く
- アイデア出しを手伝う
ChatGPTも、このLLMを使ったサービスのひとつです。たとえば「ローカルLLMとは何ですか?」と質問すると、AIがその質問の意味を読み取り、自然な文章で説明してくれます。
つまりLLMは、単なる検索エンジンではありません。インターネット上のページを探して表示するだけではなく、入力された文章をもとに、回答文そのものを作り出すAIです。
ただし、LLMは万能ではありません。間違った情報をもっともらしく答えることもありますし、最新情報に弱い場合もあります。そのため、LLMを使うときは必要に応じて自分でも確認することが大切です。
ローカルLLMとは
ローカルLLMとは、自分のパソコンや社内サーバーなど、手元の環境で動かすLLMのことです。
通常、ChatGPTのようなAIサービスを使うときは、入力した文章がインターネットを通じて外部のサーバーに送られます。そのサーバー側でAIが処理を行い、回答が返ってくる仕組みです。
一方でローカルLLMは、AIモデルを自分のパソコンにダウンロードして使います。そのため、文章の処理は基本的に自分のパソコン上で行われます。イメージとしては、以下のような違いです。
■クラウド型LLM
[自分のPC] → [インターネット] → [外部サーバーのAI] → [回答]
■ローカルLLM
[自分のPCの中にあるAI] → [回答]
ローカルLLMを使うためには、AIモデル本体と、それを動かすためのツールが必要です。今回の記事では、ローカルLLMを簡単に動かせるツールとして Ollama を使います。Ollamaを使うと、コマンドを入力するだけでAIモデルをダウンロードし、自分のパソコン上で実行できます。
たとえば今回試した qwen3:4b というモデルは、約2.5GBのデータをダウンロードして使いました。このように、ローカルLLMは、Webサイトにアクセスして使うAIではなく、AIモデルを自分のパソコンに入れて使うAI だと考えるとわかりやすいです。
クラウド型LLMとの違い
ローカルLLMを理解するには、ChatGPTのようなクラウド型LLMとの違いを知るとわかりやすいです。クラウド型LLMとは、AIの処理を外部のサーバーで行うタイプのサービスです。ChatGPT、Claude、Geminiなどが代表的です。これらは、ユーザーが文章を入力すると、その内容がインターネット経由でサービス提供会社のサーバーに送られます。そして、サーバー上にある高性能なAIが回答を作り、ユーザーに返します。
一方、ローカルLLMは、自分のパソコン上でAIを動かします。大きな違いは、AIがどこで動いているか です。
■クラウド型LLM
外部のサーバーで動く
■ローカルLLM
自分のパソコンで動くクラウド型LLMは、導入が簡単で高性能なモデルをすぐ使えるのが魅力です。アカウントを作ってブラウザからアクセスすれば、すぐに使い始められます。
一方でローカルLLMは、最初にツールやモデルをインストールする必要があります。また、パソコンの性能によって動作速度や使えるモデルの大きさが変わります。初心者向けにまとめると、次のような違いがあります。
| 項目 | クラウド型LLM | ローカルLLM |
|---|---|---|
| 動く場所 | 外部サーバー | 自分のPC |
| 導入のしやすさ | 簡単 | 少し準備が必要 |
| PCスペック | あまり関係ない | 重要 |
| インターネット接続 | 基本的に必要 | モデル導入後は不要な場合もある |
| データの扱い | 外部サーバーに送信される | 自分のPC内で処理できる |
| 性能 | 高性能なモデルを使いやすい | PC性能やモデルによる |
どちらが優れているというより、使い方が違います。手軽さや高性能を重視するならクラウド型LLM、
プライバシーや手元で動かす体験を重視するならローカルLLM、というように使い分けるのが現実的です。
ローカルLLMのメリット
自分のパソコン上で動かせる
一番大きな特徴は、AIを自分のパソコン上で動かせることです。クラウド型LLMでは、入力した文章を外部サーバーに送る必要があります。しかしローカルLLMでは、AIモデルを自分のパソコンに入れて動かすため、処理を手元の環境で完結させることができます。たとえば、個人的なメモ、日記、社外に出しにくい文章、公開前の原稿などを扱いたい場合に安心感があります。
インターネット接続なしでも使える場合がある
一度モデルをダウンロードしておけば、インターネットに接続していなくても使える場合があります。たとえば、外出先でネット環境が不安定なときや、オフライン環境で文章生成を試したいときにも使えます。ただし、最初にツールやモデルをダウンロードするときはインターネット接続が必要です。
月額料金なしで試しやすい
ローカルLLMは、無料で公開されているモデルを使えば、月額料金なしで試せるものもあります。ChatGPTなどのクラウド型サービスでは、高性能なモデルを使うために月額料金が必要になることがあります。一方でローカルLLMは、自分のPCで動かすため、モデルによっては追加料金なしで使えます。ただし、無料で使えるからといって完全にコストがないわけではありません。パソコンの性能が必要だったり、ストレージ容量を使ったり、長時間動かすと電気代がかかったりします。
AIを動かしている実感がある
これは少し個人的な感想ですが、ローカルLLMは自分のパソコンの中でAIが動いているという実感があります。コマンドを入力してモデルをダウンロードし、実際に質問して回答が返ってくると、AIを自分の環境で扱っている感覚があります。単にWebサービスとしてAIを使うだけでなく、仕組みを少し理解しながら使える点も、ローカルLLMの面白さだと思います。
ローカルLLMのデメリット
ある程度のPCスペックが必要
ローカルLLMは、自分のパソコンでAIを動かします。そのため、パソコンの性能が低いと、動作が遅かったり、モデルを読み込めなかったりすることがあります。特に重要なのは、メモリ容量とGPU性能です。軽量なモデルであれば普通のPCでも動く場合がありますが、大きなモデルを快適に動かすには高性能なPCが必要になります。
モデルのダウンロード容量が大きい
ローカルLLMでは、AIモデル本体をダウンロードして使います。今回試した qwen3:4b というモデルでも、サイズは約2.5GBありました。モデルによっては数GBから数十GBになることもあります。そのため、ストレージ容量やダウンロード時間には注意が必要です。
導入に少し手間がかかる
ChatGPTのようなクラウド型LLMは、ブラウザでアクセスすればすぐ使えます。一方でローカルLLMは、ツールをインストールしたり、モデルをダウンロードしたりする必要があります。今回使うOllamaは比較的簡単に導入できますが、それでも初心者にとってはコマンドを入力するという時点で少しハードルを感じるかもしれません。
回答品質はモデルによって差がある
ローカルLLMは、使うモデルによって回答の質が大きく変わります。軽量モデルは動作が軽い反面、難しい質問に弱かったり、日本語の自然さが足りなかったりすることがあります。逆に高性能なモデルは回答品質が高い傾向がありますが、そのぶんPCスペックやメモリを多く必要とします。そのため、ローカルLLMではどのモデルを使うかがとても重要になってきます。
最新情報には弱い場合がある
ローカルLLMは、基本的にダウンロードしたモデルの知識をもとに回答します。そのため、最新ニュースや現在の価格、最新の法律・制度などについては、正確に答えられない場合があります。これはクラウド型LLMでも起こることがありますが、ローカルLLMでは特に注意が必要です。最新情報が必要な内容は、公式サイトや信頼できる情報源で確認するようにしましょう。
導入前の準備
ここからは、実際にローカルLLMを導入する前に確認しておきたいことを整理します。ローカルLLMは、自分のパソコンにAIモデルを入れて動かす仕組みです。そのため、事前にPCスペックやストレージ容量、インターネット環境を確認しておくと安心です。今回は、ローカルLLMを手軽に導入できるツールとして Ollama を使います。
注意事項・確認事項
ストレージ容量に余裕があるか
ローカルLLMでは、AIモデル本体をPCにダウンロードします。モデルのサイズは、小さいものでも数GB程度あります。今回使用した qwen3:4b は約2.5GBでした。複数のモデルを試したくなると、10GB、20GBと容量を使うこともあります。そのため、最低でも空き容量は10GB以上、できれば数十GBほど余裕があると安心です。
インターネット環境が安定しているか
モデルをダウンロードするには、インターネット接続が必要です。モデルサイズが大きいため、回線が遅いとダウンロードに時間がかかります。今回の環境でも、モデルのダウンロードには数分かかりました。導入作業中に通信が切れると、ダウンロードが失敗する可能性もあります。できれば安定したWi-Fiや有線LAN環境で作業するのがおすすめです。
PCに負荷がかかる可能性がある
ローカルLLMは、自分のPCでAIを動かします。そのため、モデルを実行している間はCPU、メモリ、GPUに負荷がかかる場合があります。特に大きなモデルを動かすと、PCのファンが回ったり、他の作業が重くなったりすることもあります。最初は軽量なモデルから試すのがおすすめです。
会社や学校のPCではルールを確認する
会社や学校から支給されているPCにローカルLLMを入れる場合は、事前にルールを確認しましょう。ソフトウェアのインストールが禁止されている場合や、AIツールの利用に制限がある場合があります。個人のPCで試す場合でも、扱うデータには注意が必要です。
AIの回答をそのまま信じすぎない
ローカルLLMは便利ですが、回答が常に正しいとは限りません。間違った内容を自然な文章で答えることもあります。特に、医療、法律、最新ニュースなどの情報は注意が必要です。
必要なPCスペックの目安
ローカルLLMに必要なPCスペックは、使うモデルの大きさによって変わります。初心者が最初に試すなら、まずは軽量モデルから始めるのがおすすめです。
| 用途 | メモリ | GPU | 目安 |
|---|---|---|---|
| とりあえず試す | 8GB以上 | なしでも可 | 軽量モデルなら動く可能性あり |
| ある程度快適に使う | 16GB以上 | あると良い | 3B〜7B程度のモデルを試しやすい |
| しっかり試す | 32GB以上 | NVIDIA GPU推奨 | 7B〜14B程度も試しやすい |
| 大きなモデルを使う | 64GB以上 | VRAM多めのGPU推奨 | さらに大きなモデル向け |
ここで出てくる「3B」や「7B」は、モデルの大きさを表す目安です。Bは「Billion」の略で、10億という意味になります。たとえば7Bモデルは、ざっくり言うと70億規模のパラメータを持つモデルです。基本的には、数字が大きいモデルほど高性能になりやすい一方で、動かすために必要なPCスペックも高くなります。初心者の場合は、まず3Bや4Bクラスの軽量モデルから試すのが安心です。
今回使用した qwen3:4b は、約2.5GBのモデルでした。軽量モデルなので、ローカルLLMを初めて試すには扱いやすいモデルです。ただし、PCスペックが足りない場合でも、必ず動かないとは限りません。速度が遅くなる、回答まで時間がかかる、大きなモデルは読み込めない、といった形で差が出ることが多いです。
筆者のPCスペック・動作環境
今回、実際にローカルLLMを導入したPCのスペックは以下の通りです。
| 項目 | 内容 |
|---|---|
| CPU | AMD Ryzen 7 7700 8-Core Processor |
| メモリ | 約32GB |
| GPU | NVIDIA GeForce RTX 5070 |
| 使用OS | Windows |
| 使用ツール | Ollama 0.31.1 |
| 使用モデル | qwen3:4b |
| モデルサイズ | 約2.5GB |
このPCは、ローカルLLMを試すにはかなり余裕のある構成です。特にメモリが32GBあり、NVIDIA GPUも搭載されているため、軽量モデルだけでなく、もう少し大きめのモデルも試せる可能性があります。今回は初心者向けの記事なので、最初から大きなモデルは使わず、軽めの qwen3:4b を使って動作確認しました。
実際に使ってみたところ、Ollamaの導入自体はスムーズに完了しました。ただし、モデルのダウンロードには時間がかかりました。また、インストール直後はPowerShellで ollama コマンドが認識されない場面がありました。このような場合は、新しくPowerShellを開き直すと解決することがあります。このあたりは、実際の導入手順のパートでスクリーンショット付きで紹介します。
今回使うツール「Ollama」とは
今回の記事では、ローカルLLMを動かすために Ollama というツールを使います。Ollamaは、ローカルLLMを簡単にダウンロードして実行できるツールです。通常、ローカルLLMを動かすには、モデルファイルを用意したり、実行環境を整えたりする必要があります。初心者にとっては、この準備が少し難しく感じることがあります。Ollamaを使うと、コマンドを入力するだけでモデルのダウンロードから実行まで行えます。たとえば、下記のようなコマンドでモデルを実行できます。
ollama run qwen3:4bこのコマンドを入力すると、指定したモデルがPC内にない場合は自動でダウンロードされます。ダウンロードが終わると、そのままローカルLLMとして質問できるようになります。Ollamaは、Windows、Mac、Linuxに対応しています。今回の記事では、Windows環境でOllamaを導入していきます。
「ローカルLLMに興味はあるけれど、何から始めればいいかわからない」という人にとって、Ollamaは最初に試しやすいツールだと思います。
【本題】ローカルLLM導入手順
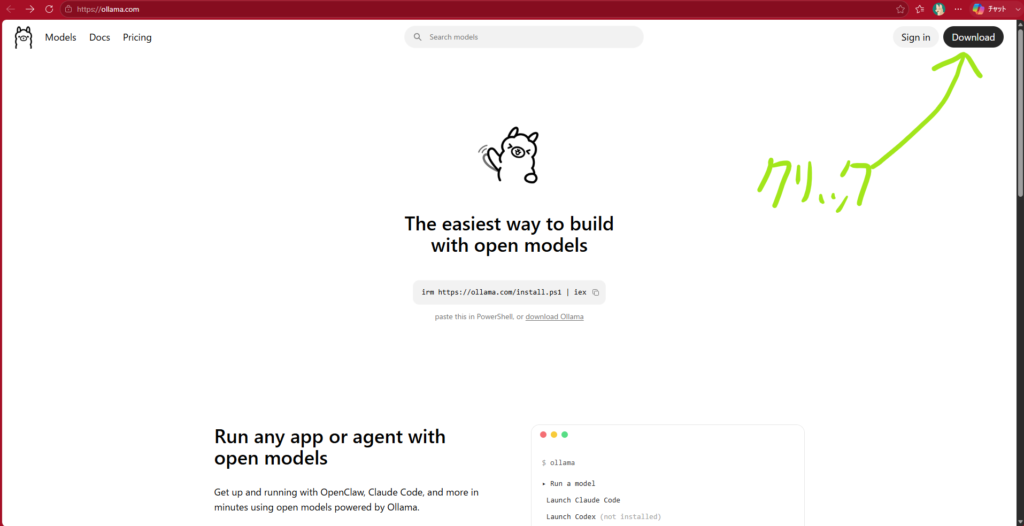
Ollama公式サイトへアクセス
■Ollama公式サイト
https://ollama.com/
公式サイトを開いたら、Windows版のダウンロードページに進みます。
Ollamaをインストールする
Windows版のページを開くと、Ollamaをインストールする方法が表示されます。Windowsでは、PowerShellに以下のコマンドを入力してインストールできます。
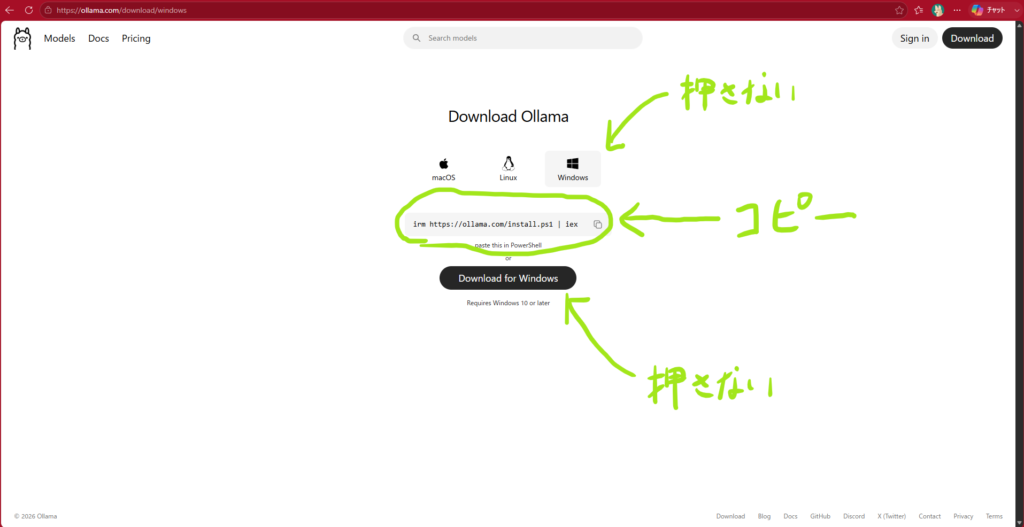
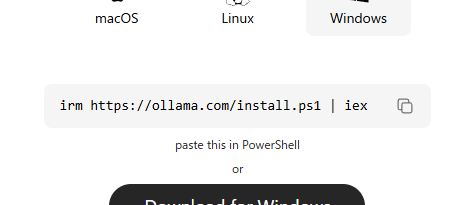
irm https://ollama.com/install.ps1 | iex(サイトにアクセスしなくても上記コマンドコピーでも可能)
このコマンドは、Ollamaの公式インストールスクリプトを取得して実行するものです。コマンドを見ると少し難しく感じますが、初心者向けに言うと、Ollamaを自動でダウンロードしてインストールするための命令 です。
PowerShellを開く
次に、WindowsのPowerShellを開きます。PowerShellは、Windowsに最初から入っているコマンド入力用のアプリです。開き方は下記の通りです。
- Windowsのスタートボタンを押す
- 検索欄に「PowerShell」と入力する
- 「Windows PowerShell」を開く
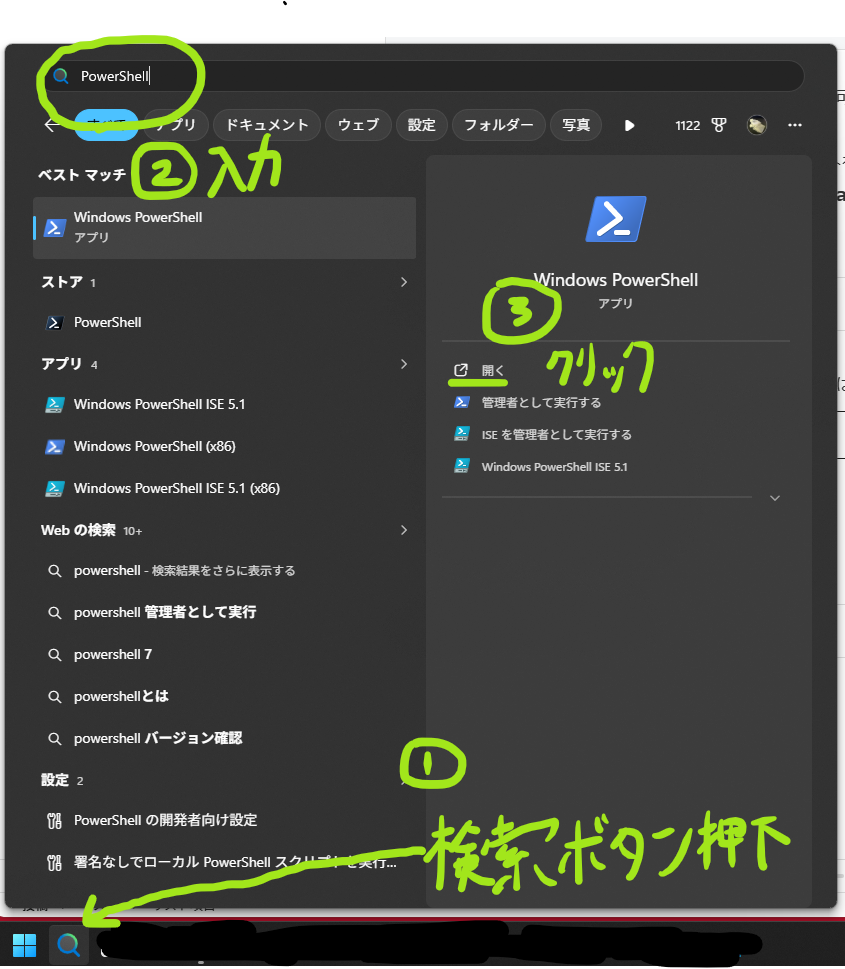
PowerShellを開くと、黒または青っぽい画面が表示されます。ここにコマンドを入力していきます。
インストールコマンドを実行する
PowerShellを開いたら、先ほどのコマンドを貼り付けてEnterキーを押します。
入力後、Ollamaのダウンロードとインストールが始まります。しばらく待つと、次のような表示が出ます。
Downloading Ollama for Windows...
Installing Ollama...
Install complete. Run 'ollama' from the command line.インストールが完了すると、PowerShellに Install Complete と表示されます。
Ollamaがインストールされたか確認する
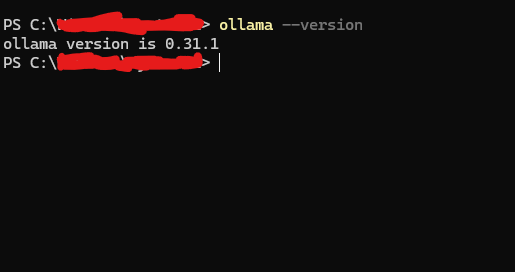
インストールが終わったら、Ollamaが正しく使えるか確認します。PowerShellで以下のコマンドを入力します。
ollama --version正常にインストールされていれば、Ollamaのバージョンが表示されます。今回の環境では、以下のように表示されました。
ollama version is 0.31.1もし ollama が認識されない場合は、PowerShellを一度閉じて、もう一度開き直してから試してみてください。インストール直後は、Windows側にコマンドの場所が反映されていないことがあります。
使用するモデルをダウンロードする
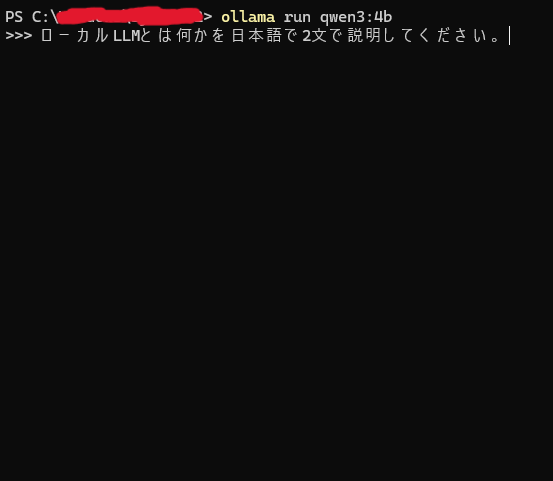
Ollamaを入れただけでは、まだAIモデルは使えません。次に、実際に動かすAIモデルをダウンロードします。今回は、初心者でも試しやすい軽量モデルとして qwen3:4b を使います。PowerShellで下記のコマンドを入力します。
ollama run qwen3:4bこのコマンドを実行すると、PC内に qwen3:4b がない場合、自動でダウンロードが始まります。今回の環境では、モデルサイズは約2.5GBでした。モデルのダウンロードには数分かかる場合があります。回線速度によっては、もっと時間がかかることもあります。途中で止まったように見えても、進行状況が表示されていればそのまま待ちましょう。
完了|実際に質問してみる
モデルのダウンロードが終わると、そのまま質問できる状態になります。試しに、以下のように質問してみます。

ここまでできれば、ローカルLLMの導入と動作確認は完了です。
モデル確認・起動・終了
PCに入っているモデルを確認してみます。PowerShellで下記のコマンドを入力します。
ollama listすると、現在インストール済みのモデル一覧が表示されます。今回の環境では、以下のように表示されました。
NAME ID SIZE MODIFIED
qwen3:4b 359d7dd4bcda 2.5 GB 18 seconds ago
ローカルLLMの起動にはモデルをダウンロードしたときと同じコマンドを入力することで起動することができます。
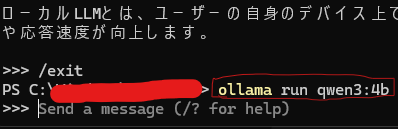
ローカルLLMを終了するには、「exit」と入力して終了します。

導入して使ってみた感想
ここからは、実際にOllamaを使ってローカルLLMを動かしてみた感想をまとめます。今回はWindows環境にOllamaをインストールし、 qwen3:4b というモデルを使って試しました。ローカルLLMは名前だけ聞くと難しそうに感じますが、実際に動かしてみると「自分のPCの中でAIが動いている」という感覚があり、かなり面白い体験でした。一方で、ChatGPTのようなクラウド型AIとは違い、導入やモデル選びには少し慣れが必要だとも感じました。
回答速度について
今回使った qwen3:4b は、比較的軽量なモデルです。筆者のPC環境では、質問を入力してから回答が返ってくるまでの速度は十分実用的でした。短い質問であれば、待たされている感覚はそこまで強くありません。たとえば、下記のように質問すると日本語で自然な説明が返ってきました。
ローカルLLMとは何かを日本語で2文で説明してください。ただし、ChatGPTのようなクラウド型AIとまったく同じ感覚かというと、少し違います。ローカルLLMは自分のPC上で処理しているため、回答速度はPCスペックや使うモデルによって大きく変わります。軽いモデルなら快適に動きますが、大きなモデルを使うと回答が遅くなる可能性があります。今回の環境では、メモリ32GBとNVIDIA GPUを搭載していたため、軽量モデルの動作はかなりスムーズでした。一方で、低スペックPCやGPU非搭載のPCでは、同じモデルでも回答が遅く感じるかもしれません。
日本語の回答品質はどうだったか
日本語の回答品質については、思っていたより自然でした。文章も大きく崩れておらず、日本語としても不自然さは少なめでした。ただし、回答の途中で英語の思考ログのような文章が出る場面もありました。モデルによっては、最終回答の前に余計な文章が表示されることがあります。また、モデルによって日本語の得意不得意は変わります。今回の qwen3:4b は軽量モデルとしては使いやすい印象でしたが、より自然な日本語を求めるなら、別のモデルも試して比較してみたいところです。
ChatGPTと比べて便利だと思った点
ChatGPTと比べて便利だと感じたのは、やはり 自分のPC上で動かせる安心感 です。クラウド型AIの場合、入力した文章はインターネットを通じて外部のサーバーに送られます。もちろん各サービスには利用規約やプライバシー保護の仕組みがありますが、それでも個人的な内容や公開前の文章を入力するのに抵抗がある人もいると思います。ローカルLLMであれば、基本的に自分のPC上で処理できます。そのため、外部サービスに貼り付けるのが不安な文章を試す用途には向いていると感じました。
また、モデルを一度ダウンロードしておけば、インターネット接続なしでも使える場合があります。ネット環境に左右されにくい点も便利です。さらに、月額料金なしで試せるモデルがあるのも魅力です。ChatGPTの有料プランと比べると、ローカルLLMは自分のPC性能を使う代わりに、無料でいろいろなモデルを試せます。AIをただ使うだけでなく、モデルを選んで動かすという体験ができるのも面白い点でした。
逆に使いにくいと感じた点
一方で、使いにくいと感じた点もあります。まず、初心者にとってはコマンド操作が少しハードルになります。Ollamaはかなり簡単に使えるツールですが、それでもPowerShellを開いてコマンドを入力する必要があります。普段コマンドを使わない人にとっては、この時点で少し難しく感じるかもしれません。
また、モデルのダウンロードに時間がかかる点も注意が必要です。今回使った qwen3:4b でも、モデルサイズは約2.5GBありました。回線速度によっては、ダウンロードに数分以上かかります。
さらに、ローカルLLMはモデルによって回答品質に差があります。ChatGPTのように、最初から高性能なAIが整った状態で使えるわけではありません。どのモデルを使うか、PCスペックに合っているか、日本語が得意か、といった点を自分で試しながら選ぶ必要があります。
もうひとつ気になったのは、回答の安定感です。今回のモデルでは、日本語の回答自体はできましたが、途中で英語の思考ログのような文章が出る場面がありました。初心者が見ると不安になるかもしれません。
このあたりはモデルの特徴でもあるため、使うモデルを変えることで改善する可能性があります。全体として、ローカルLLMはとても面白く便利ですが、ChatGPTのようにすぐ誰でも迷わず使えるサービスとは少し違います。導入やモデル選びを含めて楽しめる人には向いていますが、手軽さだけを求めるならChatGPTのほうが使いやすいと感じました。
まとめ
今回は、ローカルLLMとは何か、そして実際にOllamaを使ってローカルLLMを導入する流れを紹介しました。
ローカルLLMとは、ChatGPTのようなAIを自分のPC上で動かす仕組みです。
クラウド型LLMとは違い、AIモデルをPCにダウンロードして使うため、データを外部サーバーに送らずに処理できる点が大きな特徴です。
今回使用した環境では、Ollamaをインストールし、 qwen3:4b という軽量モデルを使って日本語の質問に回答させることができました。
初心者が最初に試すなら、Ollamaを使って軽量モデルから始めるのがおすすめです。
いきなり大きなモデルを使おうとすると、ダウンロード容量が大きかったり、PCへの負荷が高かったりします。まずは qwen3:4b のような軽めのモデルで、「自分のPCでAIが動く」という感覚を試してみるのがよいと思います。
ローカルLLMは、まだ少しマニアックな印象もありますが、実際に触ってみると意外と身近に感じられます。ChatGPTのようなクラウド型AIとは違った面白さがあるので、AIに興味がある人は一度試してみる価値があるのではないでしょうか。


コメント